
Hi,我是阿昌,今天记录分析下关于0727开发问题小结分享的内容。
总结汇总了一些在开发问题,或者需要开发注意点;
一、内容概览
● 问题驱动思维
● 数据库
● javaee & 框架
● 服务治理
● 三方服务 & 迁移操作
二、问题驱动思维
强调在开发功能或解决问题时,首先要思考可能出现的问题,并提前采取措施来避免或解决这些问题。
这种思维方式有助于提高开发过程的效率和质量。
①bug的处理方案通用方法论
- 是否可复现
- debug
a. 远程debug
b. 本地debug - 打日志
②查看是否能够增加请求入参来减少增加接口,减少系统风险【excel导出功能】
导出/test/export
1 | /** |
接口暴露风险:
- 信息泄露:未经适当的身份验证和授权,攻击者可以通过HTTP接口获取敏感信息,如用户凭据、个人数据等。
- 跨站脚本攻击(XSS):攻击者可以通过在HTTP请求中注入恶意脚本,使其在用户浏览器中执行,从而窃取用户信息或进行其他恶意操作。
- 跨站请求伪造(CSRF):攻击者可以通过伪造合法用户的请求,使其在用户不知情的情况下执行恶意操作,如修改用户信息、发起转账等。
- 拒绝服务攻击(DoS):攻击者可以通过发送大量无效请求或恶意请求,使服务器资源耗尽,导致服务不可用。
- SQL注入攻击:攻击者可以通过在HTTP请求中注入恶意SQL语句,从而绕过身份验证和授权,执行未经授权的数据库操作。
③当异步触发任务的时候,考虑服务发布重启后,是否会丢失任务
例如物流预警回调aftersale-web或dts-web的时候如果出现了问题,或服务重启就有可能出现数据丢失&异常
● 解决方案:使用MQ、mysql方案解决….
④尽量不要在公共模型里面添加默认字段,多人协同开发有可能会导致业务错乱,出现业务问题
1 | com.xxx.xxx.common.model.xx.SkuDTO |
⑤评估内存情况,避免服务器OOM,excel导入
1 | //一次性倒入 |
⑥查询拆分时,注意拆分后出现的重复问题,判断是否可以去重再拆分
● 减少调用
1 | Sets idSet = Lists.toSets(idList); |
⑦拆分处理的数据,缓存内存压力,减少等待时间,但是否需要考虑业务操作的原子性
1 | handleA(); |
⑧前端Tab页功能切换,导入旧数据请求问题
⑨核心业务和旁支业务要分离开,可用mq解耦/发布事件
1 | handleA();//主业务 |
⑩注意service逻辑所在的包,让独立的逻辑在自己的service中
11.mq消息传递用独立的对象,传递不应该传递业务模型,而是传递关键的id信息,不然可能会出现异步数据覆盖的情况
1 | private User user; |
12.批量拆分不去重,转Map会有可能出现重复数据问题
1 | beanMap = beanResp.getList().stream(). |
13.大促情况下,注意服务雪崩问题
服务雪崩:指在软件行业中,由于某个服务的故障或不稳定性导致整个系统的服务质量急剧下降或完全瘫痪的现象。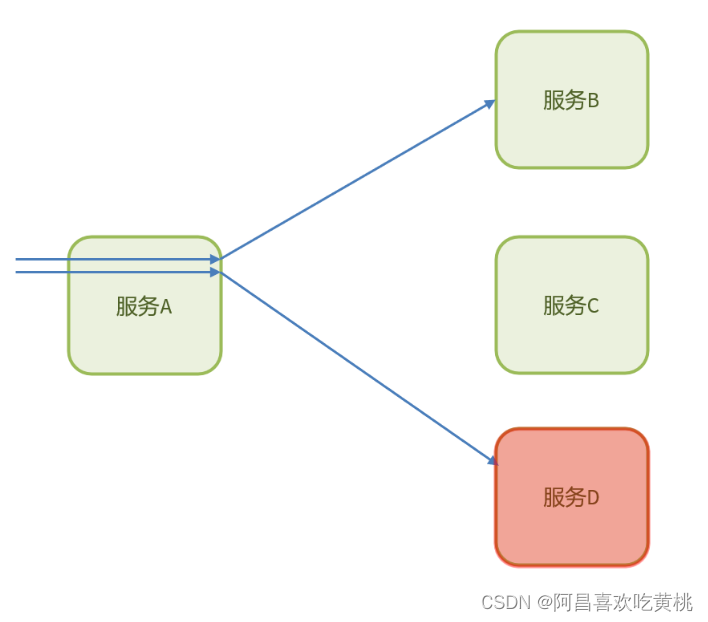
14.紧急情况下,降级流程
- 拉黑用户功能纬度
- 拉黑系统纬度
- 拉黑sql纬度
- 拉黑ip
- 杀掉实例机子
三、数据库
1.数据库字段默认尽量不要使用null,使用空串“”
优点:
- 空串“”可以作为一个有效的值,可以在查询和过滤数据时进行比较和操作。
- 使用空串“”作为默认值可以避免在查询和处理数据时出现空指针异常。
缺点: - 使用空串“”作为默认值可能会导致数据的混淆和误解。空串“”可能被误认为是一个有效的值,而实际上它只是一个空值。
- 空串“”可能会占用额外的存储空间,尤其是在大型数据库中,这可能会导致存储空间的浪费。
- 使用空串“”作为默认值可能会导致数据的不一致性。如果在数据库中有多个字段使用空串“”作为默认值,那么在查询和处理数据时可能需要额外的逻辑来处理这些空串“”。
2.减少select对应的字段,只查询想要的字段
可以减少select对应的字段,只查询想要的字段,从而提高查询效率和减少数据传输的开销。
3.根据索引去使用group by 可以减少扫描的行数,增加sql查询性能
使用索引进行group by操作可以减少扫描的行数,从而提高SQL查询的性能。
当使用group by对某个列进行分组时,数据库需要扫描整个表或者索引来找到相同值的行,并将它们分组。
如果该列上存在索引,数据库可以直接使用索引来定位相同值的行,而不需要扫描整个表,从而减少了IO操作和CPU消耗,提高了查询性能。
4.判断数据库是否可以建立唯一索引,在没做幂等处理的情况下,可报错避免一系列的并发问题
5.数据库ddl更新操作动态set时,评估需要指定set的字段值,减少执行成本
6.分表添加字段遗漏问题
7.sql连表查询时,应注意是否使用上了索引,做到小表驱动大表
8.注意sql执行是的隐式类型转换问题,会导致扫全表
1 | desc update table set id = 1 where user_id= '1222222222'; |
9.事务里面尽量避免各种count和大查询,导致事务一直阻塞
10.联合唯一索引,只要有一个项为空时,就会索引失效
在数据库中,空值是可以重复的,所以当一个列的值为空时,无法保证与其他列的组合值的唯一性。因此,当联合唯一索引中的任何一个列的值为空时,索引就会失效。
为了避免这种情况,可以在创建联合唯一索引时,对包含空值的列进行限制,例如使用NOT NULL约束来确保列的值不为空。这样可以保证索引的有效性,并确保联合唯一索引的唯一性约束得到正确的应用。
11.前一天执行sql时,评估sql的执行重量度,如果不大可当天执行
12.避免一个请求一个mysql连接,导致连接池连接被打满问题;例如:根据numIid同步业务
13.避免for循环执行io操作,如查询数据库
1 | for (String tid : tidArr) { |
14.注意数据库实例之间字符集不同导致出现数据过长无法插入的问题
15.select limit1 和count() ,前者性能更好;
在选择性能方面,SELECT LIMIT 1 比 COUNT() 更好。
SELECT LIMIT 1 是用于从数据库中选择一条记录的查询语句。它只返回满足条件的第一条记录,而不需要遍历整个表。因此,它的性能较高,尤其是在大型表中。
COUNT() 是用于计算满足条件的记录数的函数。它需要遍历整个表,并对每一条记录进行计数。在大型表中,这可能会导致性能问题,特别是当表中有大量数据时。
因此,如果只需要获取一条记录,使用 SELECT LIMIT 1 会比使用 COUNT() 更好。
16.创建时间为空时,排序乱序问题,excel导出
17、set字段如果使用updateByPrimaryKeySelective类似的方法时,因为传入模型中存在userId等公共信息,导致set时也会再set一遍userId导致性能损耗

四、javase & 框架
1.发布系统报错
java.lang.Runtime exit
真实报错:Error: Could not find or load main class org.springframework.boot.loader.WarLauncher
java.lang.Throwable
at com.xx.agent.xx.hook.safe.RuntimeHook.sendMethod(RuntimeHook.java:24)
at com.xx.agent.xx.monitor.MonitorUtil.enterMethod(MonitorUtil.java:191)
at java.lang.Runtime.exit(Runtime.java)
at java.lang.System.exit(System.java:971)
at sun.launcher.LauncherHelper.abort(LauncherHelper.java:450)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:508)
Could not find or load main class org.springframework.boot.loader.WarLauncher
解决方案:原因spring项目需要改成jar包启动
2.mapper.xml timeout标签可单独配置改sql查询的超时时间
1 | <select id="selectList" resultMap="BaseResultMap" timeout="30"> |
3.mybatis中if的int类型判断空串会导致条件失效
1 | List<User> getUsers( int id); |
1 | <select id="getUsers" resultType="User"> |
4.mysql语法中case-when写法的坑;
1 | update user set |
5.hashmap的get方法取值计算hash值,若业务组装数据匹配会区分大小写
1 | System.out.println("abc".hashCode() % 500);//354 |
6.库存上传线程池设置不合理问题new ThreadPoolExecutor(4, 4, 60L, TimeUnit.SECONDS, ItemConstant.slowQueue,new ThreadFactoryBuilder().setNameFormat(“stockUpload-pool-%d”).build()),导致一直单线程跑,出现任务积压
1 | public static final LinkedBlockingQueue<Runnable> slowQueue = new LinkedBlockingQueue<>(); |
7.线程池之间,应该思考业务是否可以共用队列,以免出现队列堆积或任务共享等问题
五、服务治理
1.避免index-dubbo服务依赖订单服务
预占库存系统设置变更;基础服务应该作为最底层,不应该依赖业务
2.处理缓存服务时,应该让一个服务处理一个服务的缓存信息,对外暴露dubbo服务查询缓存信息
3、服务顺序发布、web可同时发布
dubbo > web / task/下载中心 / consumer ….
4、尽量不改变方法传进来入参的引用,你不确定外层业务是否还会使用入参的引用
1 |
|
5、nacos开关设置要做好配置中心挂了后有符合业务的默认值返回
1 | /** |
六、三方服务 & 迁移操作
1.依赖第三方服务需要评估,如果过度依赖第三方组件很容易出问题,增加项目风险;
2.当依赖第三方服务的数据时,做好npe的返回判断兼容
3.注意平台api的增量/全量接口问题
避免先get来,库存变更为增量,出现每次修改都会库存翻倍
4.使用第三方文件系统oss时,如果不想考虑是否会掩盖,那就每次上传都用新的文件名,如时间戳
1 | //时间戳 |
5.代码迁移使用复制的方式,在功能未上线期间,如果被改变,上线合并代码时会出现冲突提示,并标上@Deprecated注解
下载中心